Apache Spark – Distributed computation of π in 8 lines of Python code
In this post I show how to write a distributed application computing an approximation of pi number though a Spark application using Python.
A brief introduction of Spark
Apache Spark is an opensource cluster computing framework supporting developers to create distributed applications. Spark applications provides performance up to 100 times faster compared to Hadoop disk-based map reduce paradigm for certain applications. It allows to load data into a cluster memory and query it repeatedly using different programming language as Python, Scala or Java.
A brief introduction of Leibniz formula for pi
This formula also called Leibniz series or Gregory–Leibniz was discovered in 16th century by Gottfried Leibniz) and James Gregory.
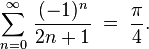
It allows summing an infinite series of numbers of compute the value of pi divided by 4.
If you sum a finite series of numbers generated using this formula you can obtain an approximation of pi number divided by 4. Increasing the number of series elements you can obtain a better approximation of pi divided by 4.
Further details about this formula are present in the Wikipedia page.
Pi approximation using Apache Spark
The following code allow to compute the pi approximation:
from pyspark import SparkContext
sc = SparkContext("local", "Pi Leibniz approximation")
iteration=10000
partition=4
data = range(0,iteration)
distIn = sc.parallelize(data,partition)
result=distIn.map(lambda n:(1 if n%2==0 else -1)/float(2*n+1)).reduce(lambda a,b: a+b)
print "Pi is %f" % (result*4)This source code computes the first 10000 values of Leibniz series and sum it. The result is multiplied for 4 in order to obtain the approximation of pi. In order to compute the 10000 values of the series, an sequence of integer between 0 and 99999 is generated and stored in distData variable. This sequence of number is splitted in 4 different partitions that could be computed separately by different servers. In order to compute the i-th element of the series I used the following map function “lambda n: (1 if n % 2 == 0 else -1)/float(2*n+1)”. The reduce function only sums the elements of the series.
In order to write the map and the reduce functions, I used lambda function python feature, in this blog i wrote a post about python lambda function. The result obtained from the reduce function is multiplied by 4 and printed to the standard output.
Development and execution environment
In order to develop and execute this application I used Spark 1.3.0
This version of Spark is present in Cloudera quickstart VM, an virtual machine appliance that contains a test environment for Hadoop/Spark clusters.
Submitting the code described in this post using this environment is very simple.
You have to write the source code in a file called for example leibniz_pi.py and execute it running the command “spark-submit leibniz_pi.py”.
The result of the execution showed in the standard output is:
Pi is 3.141493