HA two node GPFS cluster with tie-breaker disk
In a previous post I described how configure a GPFS cluster filesystem ( a filesystem that can be mounted by two or more servers simultaneously ). This article describes the changes required to enable a high-availability configuration for a GPFS cluster filesystem. This configuration allows each node to write and read the filesystem when the other node is down.
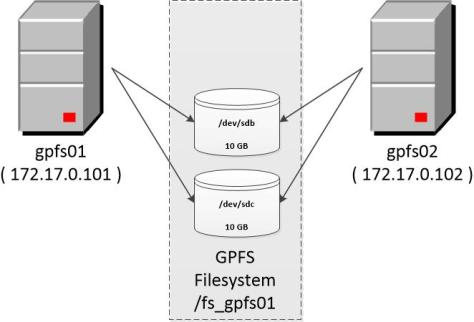
The physical server architecture, showed in the following figure, remains the same:
- two Centos server
- two shared disks between the servers
The command mmlscluster output shows that only the first gpfs node has assigned the role of manager and quorum node. In order to enable high-availability both the servers must have these two roles.
[root@gpfs01 ~]# /usr/lpp/mmfs/bin/mmlscluster
GPFS cluster information
========================
GPFS cluster name: gpfs01
GPFS cluster id: 14526312809412325839
GPFS UID domain: gpfs01
Remote shell command: /usr/bin/ssh
Remote file copy command: /usr/bin/scp
Repository type: CCR
Node Daemon node name IP address Admin node name Designation
--------------------------------------------------------------------
1 gpfs01 172.17.0.101 gpfs01 quorum-manager
2 gpfs02 172.17.0.102 gpfs02The filesystem fs_gpfs01 is composed by two network shared disk. In this post I’ll show how configure thee two disks as tie-breaker disks in order to enable the high-availability.
[root@gpfs01 ~]# /usr/lpp/mmfs/bin/mmlsnsd -a
File system Disk name NSD servers
---------------------------------------------------------------------------
fs_gpfs01 mynsd1 (directly attached)
fs_gpfs01 mynsd2 (directly attached)Indeed as many other cluster softwares GPFS requires that the majority of quorum nodes are online to use the filesystem in order to avoid split brain. In this case the cluster is composed by an even number of cluster nodes so one or more tie-breaker disk must be defined. More details about gpfs reliability configuration can be found in this document http://www-03.ibm.com/systems/resources/configure-gpfs-for-reliability.pdf .
As described before I assign the manager and quorum role to node gpfs02 and I verify it using the command mmlscluster.
[root@gpfs01 ~]# mmchnode --manager -N gpfs02
Thu May 7 22:11:20 CEST 2015: mmchnode: Processing node gpfs02
mmchnode: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
[root@gpfs01 ~]# mmchnode --quorum -N gpfs02
Thu May 7 22:11:20 CEST 2015: mmchnode: Processing node gpfs02
mmchnode: Propagating the cluster configuration data to all
affected nodes. This is an asynchronous process.
[root@gpfs01 ~]# /usr/lpp/mmfs/bin/mmlscluster
GPFS cluster information
========================
GPFS cluster name: gpfs01
GPFS cluster id: 14526312809412325839
GPFS UID domain: gpfs01
Remote shell command: /usr/bin/ssh
Remote file copy command: /usr/bin/scp
Repository type: CCR
Node Daemon node name IP address Admin node name Designation
--------------------------------------------------------------------
1 gpfs01 172.17.0.101 gpfs01 quorum-manager
2 gpfs02 172.17.0.102 gpfs02 quorum-managerI configure both NSD as tie-breaker disks and I verify it using the command mmlsconfig
[root@gpfs01 ~]# mmchconfig tiebreakerDisks="mynsd1;mynsd2"
[root@gpfs01 ~]# mmlsconfig
Configuration data for cluster gpfs01:
--------------------------------------
clusterName gpfs01
clusterId 14526312809412325839
autoload no
dmapiFileHandleSize 32
minReleaseLevel 4.1.0.4
ccrEnabled yes
tiebreakerDisks mynsd1;mynsd2
adminMode central
File systems in cluster gpfs01:
-------------------------------
/dev/fs_gpfs01Now the GPFS HA configuration is completed. I can shutdown one node and verify that the other node can write and read the GPFS filesystem.
[root@gpfs01 ~]# mmmount /fs_gpfs01 -a
Thu May 7 22:22:42 CEST 2015: mmmount: Mounting file systems ...
[root@gpfs02 ~]# ssh gpfs01 shutdown -h now
[root@gpfs02 ~]# cd /fs_gpfs01/
[root@gpfs02 fs_gpfs01]# ls -latr
dr-xr-xr-x 2 root root 8192 Jan 1 1970 .snapshots
[root@gpfs02 fs_gpfs01]# ls -latr
total 1285
dr-xr-xr-x 2 root root 8192 Jan 1 1970 .snapshots
drwxr-xr-x 2 root root 262144 May 7 21:49 .
-rw-r--r-- 1 root root 1048576 May 7 21:50 test1M
dr-xr-xr-x. 24 root root 4096 May 7 21:55 ..Furthermore the log in /var/log/messages provides more details about this event. The log below,grabbed on node gpfs02 when I shutdown the node gpfs01, shows that the node gpfs02 detected the failure of the node gpfs01 and it has been elected cluster manager.
# /var/log/messages
...
May 7 22:25:29 gpfs02 mmfs: [E] CCR: failed to connect to node 172.17.0.101:1191 (sock 42 err 1143)
May 7 22:25:39 gpfs02 mmfs: [E] CCR: failed to connect to node 172.17.0.101:1191 (sock 42 err 1143)
May 7 22:25:39 gpfs02 mmfs: [E] Node 172.17.0.101 (gpfs01) is being expelled due to expired lease.
May 7 22:25:39 gpfs02 mmfs: [N] This node (172.17.0.102 (gpfs02)) is now Cluster Manager for gpfs01.